

I am quite certain that there are many articles, posts and even books already written on that subject.
To be honest, I did not search for any of those. For some reason, I had to figure out sharding almost by myself building a customer design.
So this post will just be my way of walking through the process, and confirm that I can explain it again. If someone finds this useful, I will be happy 🙂
Here is the information I started with. We want to build an application that uses a database. In our case, we chose DocumentDB, but the technology itself is irrelevant. The pain point was that we wanted to be able to expand the application worldwide, but also to keep a single data set for all the users, wherever they were living, connecting from.
That meant finding a way of having a local copy of the data, writable, in every location we needed.
Having a readable replica of a database is quite standard. You may even be able to get multiple replicas of this kind.
Having a writable replica is not very standard, and certainly not a simple operation to setup.
Having multiple writable replicas… let’s say that even with reading the official guide from Microsoft (https://docs.microsoft.com/fr-fr/azure/cosmos-db/multi-region-writers) it took us a while to fully understand.
As I said, we chose to use DocumentDB, which already provides the creation a readable replica with a few clicks.
This is not enough, as we need to have a locally writable database. But we also need to be able to read data that is written from the other locations. What we can start with is to create a multiple ways replica set.
We could have a writable database in our three locations, with a readable copy in each of the other two regions :
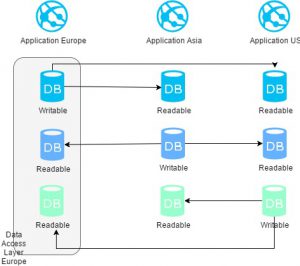
And that is where you have to realize that your database design is over.
Have a closer look at that design. Very close look. And think about our prerequisites : we need a locally writable database, check. We need to read data written from the other locations, check. We do not need to solve the last step with database mechanisms.
The final step is made in the application itself. The app needs to write into its local database to maximise performance, and limit data transfer costs between geographically distant regions. This data will then be replicated, with a small delay, to the other regions. And when the application needs to read data, it will access all of the three sets it has access to in its region, and consolidate the data from all three sets into a single view.
And there it is. Tell me now whether it was me that was a bit thick to not understand that from the Microsoft guide at first read, or please someone tell me that I am not alone in having struggled a bit with the design!
Note : this issue, at least for DocumentDB on Azure has been since solved by the introduction of CosmosDB, which provides multiple writable replicas of a database, a click away.