

If you know me, or have read some of my previous articles, you will know that I am a big fan of PaaS services.
They provide an easy way for architects and developers to design and build complex applications, without having to spend a lot of time and resources on components that may be used out of the box. And it relieves us IT admins of having to manage lower levels components and irrelevant questions. These questions are the ones that lead me to switch my focus into cloud platforms a few years ago. One day I’ll write an article on my personal journey 🙂
Anyway, my subject today concerns the later stages of the application lifecycle. Let’s say we have designed and built a truly modern app, using only PaaS services. To be concrete, here is a possible design.
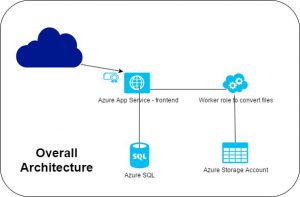
I will not dig into this design, that is not my point today.
My point is : now that it is running in production, how do you manage and monitor the application and its components?
I mean from a Managed Services Provider perspective, what do you expect of me?
I have heard recently an approach that I did not agree with but that had its benefits. I will start with this one, and then share my approach.
The careful position
What I heard was a counterpoint of the official Microsoft standpoint, which is “we take care of the PaaS components, just write your code properly and run it”. I may have twisted the words here… The customer’s position was then : “we want to monitor that the PaaS components are indeed running, and that they meets their respective SLAs. And we want to handle security, from code scanning to intrusion detection”.
This vision is both heavy and light on the IT team. The infrastructure monitoring is quite easy to define and build : you just have to read the SLAs of each component and find out the best probe to check for that. Nothing very fancy here.
The security part is more complicated as it requires you to be able to handle vulnerability scanning, including code scanning, which is more often a developer skill, and also vulnerability watching.
This vulnerability scanning and intrusion detection part is difficult, as you are using shared infrastructure in Azure datacenters, and you are not allowed to run these kind of tools there. I will write a more complete article on what we can do, and how on this front sometime this year.
Then comes the remediation process that will need to be defined, including the emergency iteration, as you will have some emergencies to handle on the security front.
The application-centric position
My usual approach is somehow different. I tend to work with our customers to focus on the application, from an end-user perspective. Does that user care that your cloud provider did not meet the SLA regarding the Service Bus you are using? Probably not. However he will call when the application is slow or not working at all, or when he experiences a situation that he thinks is unexpected. What we focus our minds on is to find out which metrics we have to monitor on each PaaS component that have a meaning about the application behavior. And if the standard provided metrics are not sufficient, then we work on writing new ones, or composites that let us know that everything is running smoothly, or not.
The next step would be, if you have the necessary time and resources, to build a Machine Learning solution that will read the data from each of the components (PaaS and code) and be able to determine that an issue is going to arise.
In that approach we do not focus on the cloud provider SLAs. We will know from our monitoring that a component is not working, and work with the provider to solve that, but it’s not the focus. We also assume that the application owners already have code scanning in place. At least we suggest that they should have it.